
This post is going to be about 'fleshing out' data we have. What I want to illustrate by writing it is that once we've collected information we can use it to get better information. This is really vital to using it effectively to draw meaningful conclusions. There are two ways to do this: 1) Looking between data we know and 2) Using what we know about the relationship between variables to infer more information.
Imagine we took a walk. We recorded the altitude along the way: at the start, in the middle and at the end. At the start of the walk (A) we measured the altitude to be 5 units. In the middle of the walk (B) we measured it to be 0 units and at the end (C) we measured it to be -5 units. We have some useful data about the path we've travelled. What if we want to know what the shape of the land surface we walked through was(without taking a measurement at every point)? To do this we can use some maths. We can interpolate between and around these points to get an idea of what it might look like. We can the take an informed guess at the value we would have measured at some other point, say D. Here's a cartoon of the walk we just took:

In the plot below I've used an interpolation method to do just this. The colour of the dots A, B, and C represents the altitudes we measured on our walk. The colour of the surface is the interpolated landscape. It uses the information we know, i.e. the altitude at points A, B, and C. and the distance between them to fill-in the gaps. The point in the middle is our unknown-altitude point D. Our model here suggests that if we had walked to point D and taken a reading the altitude would most likely be close to 0 units (shown by its colour).

{kind=link}
The picture will be different if we collect more points along the away. For example if we had taken a detour between A and B and found the altitude at this new point to be 3 units. Then it we interpolate through these points we get a change in the landscape but here it is still likely that our point D is around 0 units.

{kind=link}
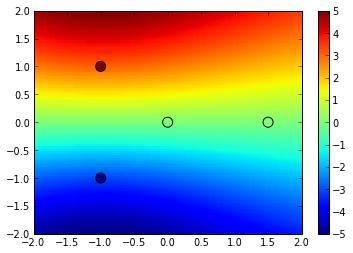
The picture though can change dramatically if we take more points. Say we took the altitude at home just before we started the walk (the point in the top-left-hand corner below) and measured it as -5 units. Our interpolated, general picture of the landscape changes a lot very quickly. Now point D is more like 4 units than 0.

{kind=link}
This general method for using the data we have for interpolating for data we don't have is crucial. With it we can make much better use of the information available to us. It does however assume that we know nothing about the context of the data. Say, for example we know that any land at an altitude of -3 units is always unstable so cannot exist. Then we know something about the system we are collecting data in. Having this information often allows us to make much better guesses at the values we haven't recorded. Using this information is the process of modelling.
For an example let's take Isaac Newton's second law of motion with acceleration as the subject:
Acceleration = Force/Mass
This relation says something about the way changes in the forces acting on an object and the object's mass will effect its acceleration. We can use this to predict what the acceleration will be for any given force. So we can use information we collect, say about the acceleration of a car and its mass, to infer the force acting on it. This is a very simple example of a model.
The most advanced method of data assimilation involves one more step. It takes into consideration one of the most important and fascinating discovery of maths of the last 100 years. In fact it was discovered by a meteorologist! Edward Lorenz. He noted that the equations that govern climate, i.e. the known relations that we are using in our models, are incredibly sensitive to the data we are putting in at the start. Even a minor change will result in a dramatically different outcome. In fact the uncertainties inherent to our data collection process make this a really significant consideration. Not only is recording data difficult, making a note of the exact value of some condition (for example temperature at the top of Gower Street) is impossible! The equations we are using are so sensitive that the number of decimal places required to get the exact value is infinite. We can't even measure it exactly let alone write it down! So, to take account for this an ingenious method has been developed. This is the last thing I going to write about in the context of data assembling.
Instead of giving up saying that we can't predict anything because of Lorenz's chaos we collect our data as accurately as possible and then make lots of little changes to it. These are called perturbations. This way we have a better idea at what the actual value (of say temperature at the top of Gower Street actually was). We put all these sets of data through our model to look at the range of outcomes and how much these differences actually matter. If we want we can then take the average of all these results to get a probability forecast rather than the deterministic one we would have if we used only one set of data.
The plot below, taken from some research I did over the summer, shows exactly this! The navy blue line starting off the East coast of Africa is the actual path of Hurricane Bill in 2009. All the other lines are forecast tracks. That is they are informed guesses at where Hurricane Bill might have gone based on information collected when the Hurricane was just north of the Caribbean. As much data as possible is collected and then it is changed a little bit, lots of times, exactly as described above, until there are 51 sets of perturbed data and the model is run for each one. The profound effect of all these changes, and the sensitivity of the model to the input data, is shown really nicely in this plot by the spread in the hurricane tracks. Some find Bill going towards Spain and some find Bill going north of Scandinavia.

Again, so what's the point of me writing about this? The point is that not only do we now have the ability to record and store more information than ever before. We also have the ability get more out of it. These techniques that I've described are fundamental to using data. The first method, interpolation, is really useful but it is limited. We can only look between the data points we already know - we can't extrapolate. The second method of modelling is extremely powerful. Our ability to run good models depends a lot of the computers we have. These are getting more and more powerful. Our models are getting better and better. This should (and it is) be a major area of focus, research and investment.
Hopefully now I've described effectively the process of data collection and assimilation. I also hope I've highlighted how uniquely positioned Society now is in terms of knowing what has happened, what is happening and what might happen in the future. The benefits of integrating and operating systems to monitor the globe, to store and assimilate this information are myriad and profound.
For my next post I'm going to look into physical engineering structures that don't passively observe but rather actively engage with, use and control their environment.
############################
I've posted the code I wrote for the above interpolation examples at: http://herculescyborgcode.blogspot.co.uk/2013/10/data-assimilation-interpolation-example.html
Like always please leave comments, suggestions or criticisms below or email them to me. I really appreciate this.
No comments:
Post a Comment